

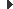
Aplicacions amb BD no orientades a objectes
La persistència mitjançant fitxers és més que suficient si el tractament que es vol fer de les dades és totalment seqüencial: l’aplicació llegeix el fitxer en la seva totalitat i a partir del seu contingut genera el conjunt d’objectes que necessita per dur a terme la seva tasca. Per exemple, un editor estàndard de textos o gràfic. Però en cas que es vulgui fer un accés aleatori a diferents parts del fitxer, o quan el nombre de dades és realment molt gran, tant que carregar tot el fitxer superaria la memòria de l’ordinador, la utilitat d’aquest sistema cau en picat.
Una altra restricció molt important és que usar fitxers deixa de funcionar, o si més no, la seva gestió es fa massa complicada perquè realment valgui la pena, quan diverses aplicacions volen accedir concurrentment a les dades emmagatzemades. És per aquest motiu que la majoria d’aplicacions que necessiten gestionar una gran quantitat d’informació o poden existir accés concurrent utilitzen una base de dades per aconseguir la persistència.
Les files d’una BD relacional també s’anomenen tuples.
Una base de dades (BD) és un mecanisme per emmagatzemar informació de manera que sigui fàcil i eficient de recuperar. En la seva accepció més simple, la de base de dades relacional, aquesta pren la forma d’un seguit de taules formades per files i columnes.
Quan parlen de BD, ens referim sempre a una BD relacional.
Al contrari del que passava amb la persistència mitjançant fitxers o la seriació d’objectes, quan s’utilitza persistència mitjançant una BD, no es tracta de recuperar immediatament tots els objectes emmagatzemats i instanciar-los a memòria. Justament, una BD s’utilitza especialment quan hi ha massa objectes o diferents equips han d’accedir a les mateixes dades, pel que fer-ho no té sentit, ja que no soluciona el problema. La part del Model que es vol que sigui persistent sempre és en la BD, i quan s’instanciï un objecte, normalment serà per encapsular un conjunt d’informació recuperada de la BD per poder operar amb les seves dades de manera temporal.
BD
A part de les BD relacionals, també hi ha les orientades a objectes i les jeràrquiques, que estructuren les dades de manera diferent, en lloc de només taules.
També és important mantenir la consistència entre els objectes a memòria i la seva representació en la BD, si en algun moment es dóna el cas que durant l’execució de l’aplicació hi ha aquesta duplicitat. Si el valor d’algun atribut de la instància a memòria varia, tard o d’hora aquest nou valor s’ha de veure reflectit en la seva representació en la BD. !
La manera en què realment s’emmagatzema i s’accedeix a tota aquesta informació depèn de l’anomenat sistema gestor de base de dades, o SGBD (database management system, o DBMS, en anglès). L’aspecte que cal destacar d’aquest sistema és que és totalment transparent al desenvolupador d’una aplicació que accedeix a la BD. Ell s’encarrega de resoldre tots els aspectes vinculats a la integritat com, per exemple, que no es repeteixin claus primàries, o l’accés concurrent a les dades.
Les capacitats de cada SGBD i com funcionen internament depèn totalment de cada fabricant. De fet, força aspectes del mateix accés al sistema varien segons el fabricant, pel que només es pot fer una descripció genèrica en els aspectes més senzills. Pels aspectes vinculats al tipus de SGBD concret, aquest text es basa en la distribució de codi obert Apache Derby, desenvolupada totalment en Java.
Traducció del Model a una BD relacional
El fet que una BD estructuri la informació en forma de taules implica un procés de transformació des de la manera en què els objectes s’estructuren a memòria, el Model, a com s’organitzen en una BD:
- Cada classe instanciable del Model es materialitza en una taula en la BD.
- Cada atribut definit en una classe es materialitza en la BD com una columna dins la seva taula.
- La persistència de cada objecte del Model es materialitza en la BD en una fila dins la taula que correspon a la seva classe. En cada cel·la de la taula s’emmagatzema el valor que cada objecte en concret té assignat a l’atribut.
Hi ha una nomenclatura formal per representar gràficament BD. S’anomena model entitat-relació.
La figura mostra un exemple senzill de traducció de classe a taula d’una BD. Cada fila correspon a la persistència de tres instàncies diferents de la classe Client.
En la BD hi ha tantes taules com tipus d’objectes es vol emmagatzemar. Quan es vol recuperar un objecte emmagatzemat, simplement se cerca en la taula corresponent per obtenir els valors dels seus atributs, de manera que si cal es pugui instanciar.
Per cercar un objecte concret en una taula, és molt important que sempre hi hagi algun atribut que sigui únic per a cada instància, de manera que no hi hagi cap ambigüitat. La columna que l’emmagatzema és el que es coneix com la clau primària d’una taula.
La necessitat de la clau primària està justificada pel fet que, en usar taules per emmagatzemar els objectes, aquests deixen de tenir referències que els identifiquin de manera única i mitjançant les quals s’hi pugui accedir. Per tant, cal afegir algun identificador únic que faci el mateix servei que una referència quan el Model es troba en la memòria. Normalment, s’escull un identificador de tipus enter, ja que ocupa poc espai i és fàcil de comparar.
La desaparició de les referències en traspassar un model orientat a objectes a taules dins una BD també té un efecte especialment important en les associacions entre classes: els atributs que conformen llistes d’altres objectes. La traducció d’una associació varia segons la seva cardinalitat, però per tots els casos cal incloure els identificadors únics, les claus primàries, d’elements d’una taula en altres taules. Aquests identificadors que delimiten elements d’una altra taula s’anomenen claus foranes.
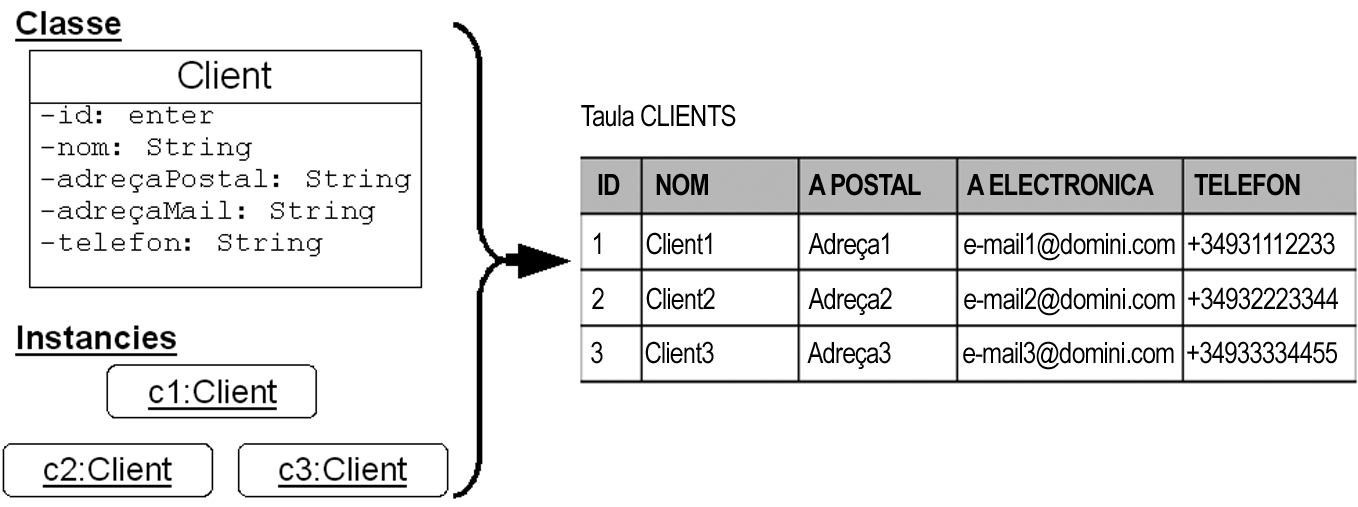
Quan la cardinalitat en un dels extrems de l’associació a traduir és unitària, 1 o 0..1, llavors, donades dues taules A i B, que representen dues classes relacionades per una associació en el diagrama estàtic UML, es faria el següent:
- Escollir la taula associada a la classe oposada a la que té cardinalitat unitària. Suposem que aquesta taula és A.
- Afegir a la taula A una nova columna, en què s’emmagatzemen claus primàries de la taula B. Mitjançant aquesta nova columna és com es referencien a partir d’ara els elements de la taula A.
- No cal fer res en la taula B.
- Si els dos extrems de la relació són unitaris, es pot escollir indistintament qualsevol taula per incloure la clau primària de l’altra.
La figura mostra un exemple que aclareix molt millor aquest procés. En aquesta figura, d’acord amb els passos indicats, la taula ENCARRECS correspondria a la taula A de la descripció i CLIENTS, en tenir la classe que representa cardinalitat unitària a l’associació, la taula B.
Per enumerar els encàrrecs d’un client determinat, només cal saber-ne l’identificador, i llavors llistar totes les files de la taula d’encàrrecs que tenen aquest identificador en la columna IDCLIENT. En aquest exemple, IDCLIENT és una clau forana a la taula ENCARRECS.
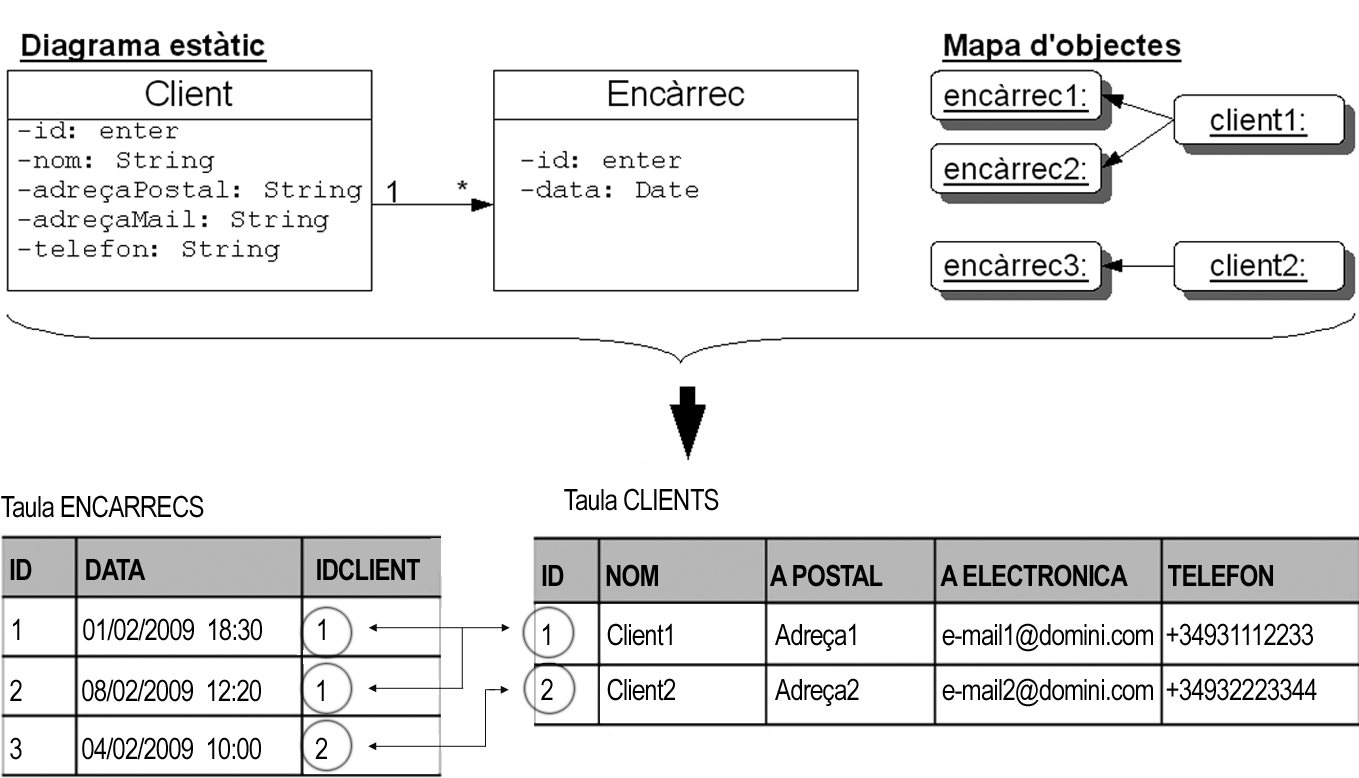
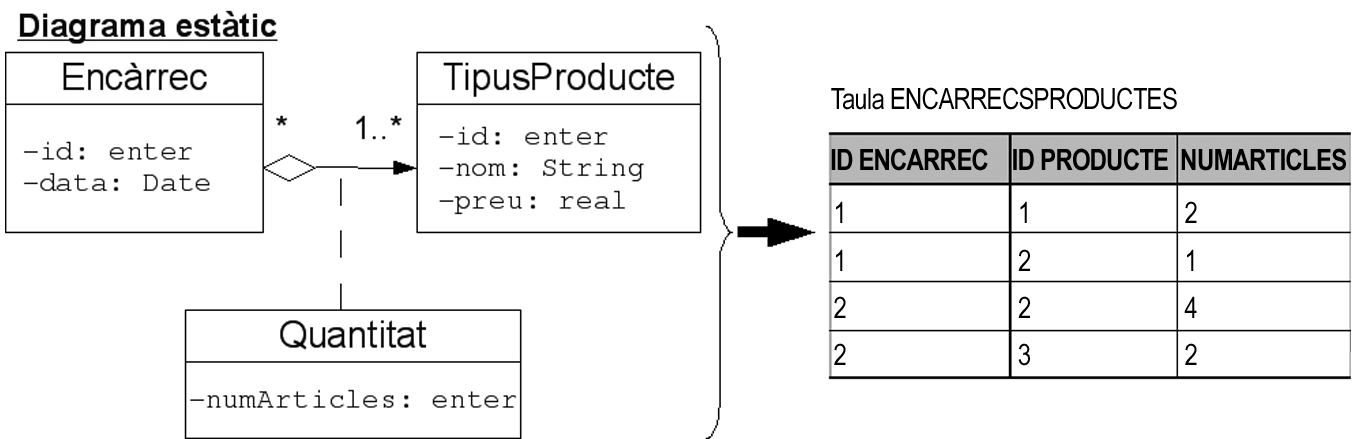
El cas d’una associació en què els dos extrems tenen cardinalitat múltiple, 1..* o *, és una mica més aparatós, ja que requereix la intervenció d’una nova taula dedicada exclusivament a enumerar totes les relacions entre elements de les dues taules associades usant-ne les claus primàries. Cada fila representa una associació entre dos elements. La figura aclareix aquest cas:
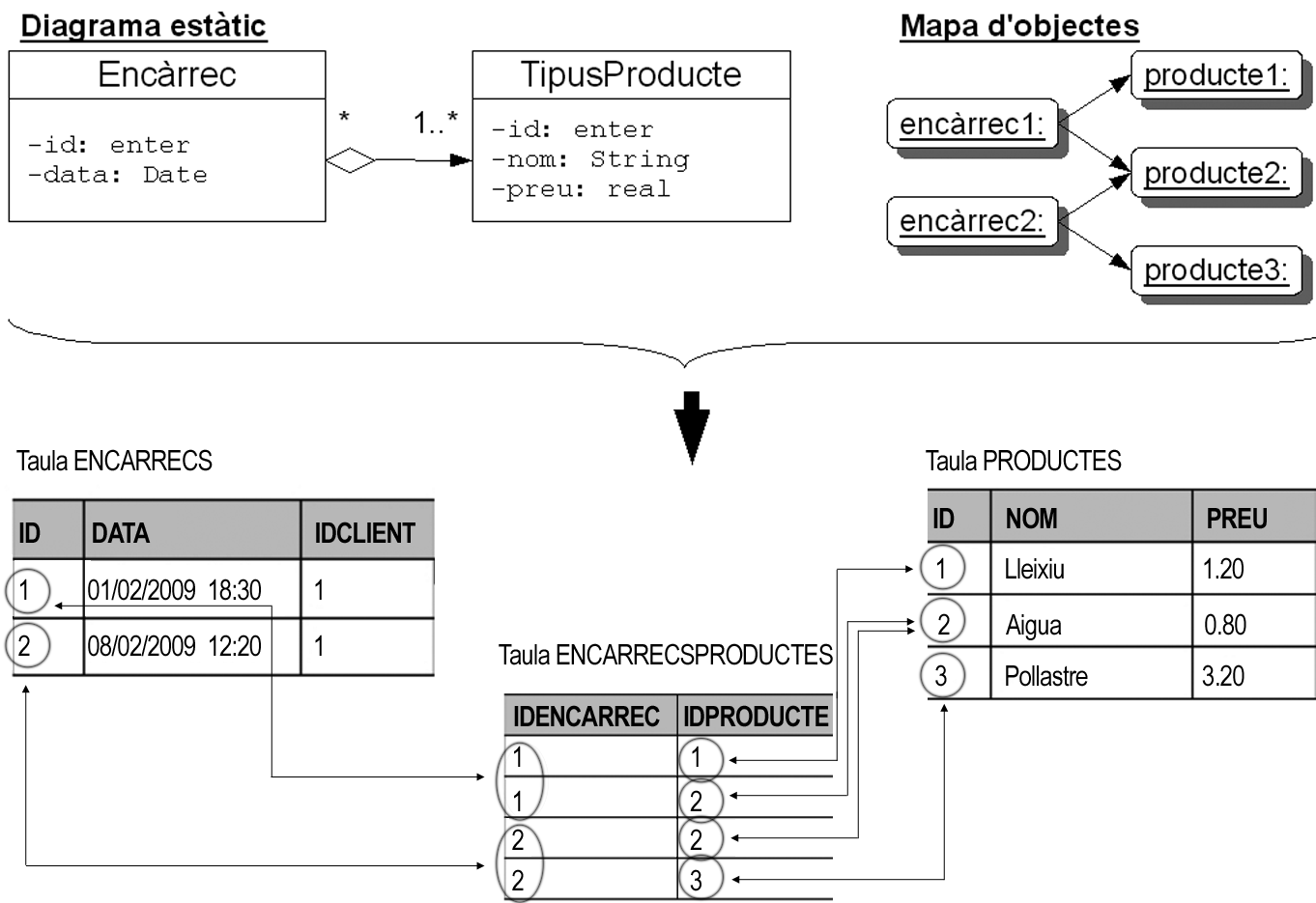
Aquest sistema també permet traduir fàcilment a taula una classe associativa, ja que en el fons no és més que un conjunt d’atributs vinculat a una associació. Per tant, com es pot veure en la figura, el mecanisme és el mateix, però afegint noves columnes d’acord amb els atributs definits en la classe associativa.
Finalment, queda exposar el cas especial de les relacions d’herència. Malauradament, l’herència és una propietat exclusiva de l’orientació a objectes, pel que no es pot traduir totalment a un model relacional. Només es pot intentar simular de la millor manera possible. Per fer-ho, hi ha dues possibilitats.
D’una banda, es pot crear una taula diferent per cada classe instanciable, de manera que els objectes s’inclouran en la taula que correspongui d’acord amb el seu tipus exacte (la subclasse més concreta). Això té l’inconvenient que en les taules relatives a classes més concretes hi haurà columnes que ja apareixen en les taules de classes més generals. A més a més, quan calgui fer operacions en les taules d’un tipus d’objecte concret que estigui en les zones més generals de la jerarquia, cal mirar cada taula.
D’altra banda, en lloc de crear diverses taules, se’n pot crear una de sola amb tots els objectes a dins. Les columnes que es definiran correspondran a l’agregació de tots els possibles atributs dins la jerarquia d’herència. Això estalvia tenir columnes repetides, però implica que hi haurà elements amb valors nuls per a certes columnes (ja que pel seu subtipus no els correspon tenir cap valor). Per tant, cal tenir-ho ben present en fer consultes i modificacions a la taula.
En qualsevol cas, sempre que es recuperin dades de les taules de la BD i es vulgui instanciar un objecte que forma part d’una jerarquia d’herència, el desenvolupador haurà d’establir alguna manera d’identificar a quina subclasse concreta pertany cada fila d’una taula.
El llenguatge SQL
Tot i les particularitats de cada fabricant, hi ha un llenguatge genèric que permet efectuar les accions més bàsiques amb una BD: el llenguatge SQL.
SQL
Si bé aquest llenguatge és un estàndard, cal tenir en compte que cada fabricant disposa de les seves extensions propietàries, totalment incompatibles entre elles.
L’SQL (structured query language, llenguatge de consultes estructurades) és un llenguatge estàndard per a l’accés a BD relacionals, de manera que és possible operar-hi: consultar les dades emmagatzemades, modificar-les…
Una sentència SQL no és més que una cadena de text, amb una sintaxi concreta, que indica un seguit d’ordres a la BD. En aquest sentit, no és gaire diferent d’un petit bocí de codi d’un programa. Aquesta sintaxi SQL és molt extensa i es poden escriure llibres sencers descrivint-ne totes les funcionalitats. En aquest apartat només es fa un breu incís sobre quines són les operacions mínimes indispensables i la seva sintaxi més bàsica. El suficient per entendre com es poden desenvolupar aplicacions en Java que utilitzin accés a una BD. Les operacions que permet SQL es poden dividir en dos tipus. D’una banda, les que componen el llenguatge de definició de dades (data definition language, o DDL), que serveixen per afegir informació a la BD, principalment per gestionar taules. D’altra banda, hi ha les que formen part del llenguatge de manipulació de dades (data manipulation language, o DML), que permeten llegir o modificar el contingut de la BD.
De moment veurem quina mena de sentències SQL accepten les BD, i després ja veurem com és possible agafar el text d’aquestes sentències i executar-les sobre la BD mitjançant codi Java.
Tipus de dades
Abans de poder crear cap taula, cal decidir quin és el tipus de les dades que conté a cadascuna de les seves cel·les (igual que cal triar els tipus de dades dels atributs a les classes). Els tipus de dades disponibles i quines són les seves paraules clau són específics a SQL, i per tant, no es pot reusar la nomenclatura de Java o UML. A més a més, cal tenir en compte que cada fabricant de BD defineix els seus propis tipus, per la qual cosa la llista pot variar segons el sistema utilitzat. Cal consultar la documentació de la BD per saber quins hi ha disponibles. De totes formes, tot seguit es llisten els que normalment podreu usar quan treballeu amb els mecanismes que proporciona Java per accedir a BD.
| Tipus | Descripció | Tipus Java semblant |
|---|---|---|
| CHAR(mida) | Cadena de text de mida fixa. | String |
| VARCHAR(mida) | Cadena de text de mida variable. | String |
| LONG VARCHAR(mida) | Cadena de text arbitràriament llarga, de mida variable. | String |
| BINARY | Bloc binari curt de mida fixa. | byte[] |
| VARBINARY | Bloc binari curt de mida variable. | byte[] |
| LONG BINARY | Bloc binari llarg de mida variable. | byte[] |
| BIT | Un bit, que pot ser només 0 o 1. | boolean |
| TINYINT | Enter de 8 bits, entre -128 i 127. | |
| SMALLINT | Enter de 16 bits, entre -32768 i 32767. | short |
| INTEGER | Enter de 32 bits, entre -2147483648 i 2147483647. | int |
| BIGINT | Enter de 64 bits. | long |
| REAL | Real de simple precisió. | float |
| DOUBLE | Real de doble precisió. | double |
| DATE | Una data consistent en dia, mes i any. | java.sql.Date |
| TIME | Temps consistent en hora, minuts i segons. | java.sql.Time |
| TIMESTAMP | Combinació de DATE i TIME, i, a més a més, el seu equivalent en nanosegons. | java.sql.Date |
Vegem amb una mica més de detall algunes de les característiques més rellevants de cada tipus de dades, que caldrà tenir en compte en programar en Java aplicacions que gestionen dades dins una BD usant SQL.
Tipus relatius a cadenes de text
El tipus VARCHAR sol ser el més típicament usat per desar cadenes de text a la BD, i està suportat de totes les principals bases de dades. En definir-lo, cal usar un paràmetre que especifica la longitud màxima de la cadena. Per tant, VARCHAR (25) defineix una cadena la longitud de la qual pot ser de fins a 25 caràcters. Ara bé, cal tenir present que les BD solen tenir un límit en la mida màxima que poden suportar, que sol rondar els 254 caràcters. Tot i definir aquesta mida màxima, sempre que es desa un valor a una cel·la d’aquest tipus, quan posteriorment es consulta aquest valor, la cadena de text retornada té com a mida el seu valor original al ser desada. No s’“omple” artificialment amb espais o altres caràcters fins arribar al màxim.
En contrast, les cadenes de longitud fixa, usant el tipus CHAR, sí que sempre mantenen la seva longitud indicada en ser introduïdes, i posteriorment consultades, a la BD, i per tant, si el nombre de caràcters és inferior al valor especificat, la resta de posicions s’omplen amb espais en blanc fins arribar a la mida definida. La seva mida màxima també sol ser de 254 caràcters. Per tant, donades les definicions VARCHAR(10) i CHAR(10), si desem el text “Hola” a la BD, en consultar posteriorment el valor, en el primer cas s’obtindrà “Hola”, mentre que en el segon “Hola ”. Això és un fet que cal tenir molt en compte.
Finalment, el tipus LONGVARCHAR, en canvi, ve justificat perquè totes les principals bases de dades han de suportar algun tipus de gran cadena de gran longitud. Per “gran longitud” s’està referint a mides de fins un gigabyte.
Tot i aquestes particularitats, en general, a un programador en Java no li cal distingir entre els tres tipus de dades a l’hora de gestionar les dades, totes elles es poden expressar dins el codi del programa com un tipus String o directament a un array de char (char[]).
A SQL els literals de cadenes de text s’especifiquen entre cometes simples, '…’
Tipus relatius a cadenes binàries
Els tres tipus vinculats a valors binaris segueixen una filosofia molt semblant a les cadenes de text, al menys en el que es refereix al seu aspecte de cadena de mida fixa o variable. Per tant, una dada del tipus BINARY es farceix amb valors addicionals fins fer-la arribar a la mida establerta. Ara bé, desafortunadament, l’ús d’aquests tipus de binaris no ha estat estandarditzada i el seu suport varia considerablement entre les principals bases de dades. Per tant, és imprescindible mirar-ne la documentació, ja que el que s’aplica per a un cas pot no ser cert per a un altre. Fins i tot, pot ser que una BD no implementi alguns d’aquests tipus.
De manera semblant a les cadenes de text, els tipus BINARY i VARBINARY solen estar limitats a 254 bytes, mentre que LONGVARBINARY es pot usar per a mides arbitràriament grans, normalment fins a un gigabyte de dades. En qualsevol cas, les dades relatives a aquests tipus es poden gestionar dins d’un programa en Java usant arrays de byte (byte[]).
Finalment, el tipus BIT és especial, ja que gestiona un únic valor binari, 0 o 1. Per aquest motiu, tot i no ser estrictament el mateix, el tipus de dades recomanat per gestionar-lo dins un programa en Java és el boolean. Es pot fer que true equivalgui a 1 i false a 0.
Tipus relatius a valors numèrics
Tots els tipus associats a valors numèrics, ja siguin enters o reals, es comporten de manera molt similar, ja que existeix una correspondència pràcticament immediata entre el tipus de dades SQL i els tipus de dades que proporciona Java. Per tant, saber com gestionar dades d’aquests tipus en programes que accedeixen a una BD no és gaire difícil. Només cal usar el tipus equivalent i ja està, sense cap complicació extra.
L’únic cas on cal anar amb compte és per al tipus TINYINT, de 8 bits, ja que el tipus de valors enters més petit en Java, el short, és de 16 bits. De cara a consultar valors des de la base de dades no hi ha cap problema, però en emmagatzemar-ne, cal ser conscients que si el valor enter a desar és superior al rang possible (-128 i 127), el valor que acabarà a la BD no serà correcte. De fet, a nivell general, com passa en fer conversions entre tipus numèrics en Java, si en consultar un valor de la BD s’usa una variable d’un tipus amb major capacitat, mai no hi haurà problemes, per la qual cosa res no impedeix usar un double Java per consultar valors de tipus REAL.
Tipus relatius a dates
Finalment, entre els tipus bàsics de SQL es troben uns d’especials que serveixen per gestionar valors de dates. Si bé, dins una aplicació Java genèrica, l’ús de dates no ha de ser necessàriament molt usat, a les BD molt sovint sí que cal desar dates, per la qual cosa tenir un tipus especial només per a això està bastant justificat i facilita molt la feina (més que haver de desar per separat cada part o usar cadenes de text amb cert format).
El tipus DATE representa una data que consta de dia, mes i any, mentre que el tipus TIME indica només hores, minuts i segons. Com ja passava amb altres tipus de dades, aquests s’implementen per només un subconjunt de les bases de dades principals. Algunes bases de dades ofereixen alternatives de tipus SQL que serveixen per al mateix propòsit. El tipus TIMESTAMP és una combinació dels dos, però està suportat per un nombre molt petit de bases de dades i per tant no és gaire recomanable dependre’n molt. Aquest darrer tipus, junt amb les dades relatives a data i temps, també desa un camp auxiliar on es compta fins a una precisió de nanosegons.
Vigileu especialment si useu els mecanismes de correcció automàtica del Netbeans.
Java proporciona tres classes que serveixen específicament per tractar aquests tipus de dades SQL (i només per al cas d’SQL): java.sql.Date, java.sql.Time i java.sql.Timestamp, ja que les seves classes per gestionar dates a nivell genèric no encaixen exactament en els seus camps amb aquests tipus. Per tant, alerta, cal anar amb molt de compte amb la classe que s’usa per gestionar dades d’aquests tipus als vostres programes, ja que, per exemple, en Java hi ha dues classes anomenades Date. Una al package java.util i una altra al java.sql.
Cal dir que, tot i que aquestes tres classes, de fet, hereten de java.util.Date, i, per tant, en el pitjor cas sempre és possible fer conversions entre elles d’alguna manera (consultant les dades dins l’objecte i adaptant-les al nou format), sempre és preferible usar la classe vinculada exclusivament a SQL.
Dominis
A més dels tipus de dades predefinits, existeix la possibilitat de treballar amb dominis definits per l’usuari, on s’especifiquen un conjunt de valors concrets possibles. Per exemple, suposeu que voleu definir un camp on els únics valors possibles són un conjunt de ciutats concret i no voleu definir el tipus com un VARCHAR, on es podria escriure qualsevol cosa. En aquest cas, usar un domini seria la solució ideal. Per fer-ho cal usar la sentència CREATE DOMAIN sobre la base de dades.
Els valors “nomDomini” i “nomRestricció” els trieu vosaltres (un cop definits, es poden usar en altres comandes). El “tipus de dades” correspon al tipus genèric al qual pertanyen els valors que es volen concretar. Per exemple, per al cas de noms de ciutats, podria ser VARCHAR (25), si cap nom supera els 25 caràcters. El paràmetre de “condicions” indica què ha de complir un valor dins aquest domini per ser considerat vàlid. SQL contempla una sintaxi per establir comparacions i avaluar diferents condicions lògiques complexes (AND, OR…). De totes maneres, normalment per a aquest cas el que se sol fer és indicar directament una llista de valors, mitjançant la sentència VALUE IN, on s’inclou entre parèntesis els valors acceptats. Per exemple:
Quan es defineix un domini, aquest es pot usar a nivell de sintaxi de les sentències de gestió de taules exactament igual que qualsevol altre tipus SQL. Per tant, donat el domini de ciutats, es pot usar “ciutats” com si fos un tipus de dades.
Si mai es vol eliminar la definició d’un domini a la nostra BD, es pot usar la sentència DROP DOMAIN.
Aquesta necessita un paràmetre, que pot ser RESTRICT o CASCADE. En el primer cas, el domini només s’esborrarà realment si no s’usa enlloc de la BD (a cap taula). En el segon cas, s’esborrarà encara que estigui en ús, però allà on es doni aquest cas, es reemplaça automàticament pel tipus de dades associat al domini. Per exemple, si s’elimina el domini “ciutats”, a totes les taules on s’usin les columnes passaran a ser del tipus VARCHAR(25) automàticament, ja que no poden quedar simplement sense cap tipus definit.
Gestió de taules
Per poder accedir a qualsevol dada dins els vostres programes, evidentment, abans de res aquestes dades han d’existir dins taules a la BD relacional. Normalment, les taules es creen a priori, i ja existeixen abans que la vostra aplicació hi interactuï. Per fer-ho, existeixen diferents programes que, mitjançant una interfície gràfica, permeten editar les propietats de les taules de les quals es vol disposar (noms de files, columnes…). Els IDE complexos com Netbeans incorporen ja una funcionalitat a aquest efecte, per tal de facilitar la feina.
De totes maneres, hi pot haver casos on pot ser necessari crear taules. El cas més immediat seria si precisament el que es vol és inicialitzar el sistema gestor de bases de dades, però fer-ho manualment és molt complicat o costós, o depèn de molts paràmetres que poden variar segons el cas. En aquest cas, res millor que un programa per automatitzar la feina. Per tant, és interessant donar una ullada a les sentències SQL per crear, esborrar i modificar les diferents taules que componen una BD.
Creació de taules
Per crear una taula s’usa la sentència CREATE TABLE, d’acord amb una llista de noms de columna i el tipus de dades que conté. Per a cada parell de noms de columna i tipus de dades es poden incloure un seguit de paràmetres per especificar informació addicional, com quina correspon a la clau primària, quin és el tipus de dades que es pot emmagatzemar, la seva mida màxima…
Els camps de valor per defecte i de restriccions són opcionals.
Per al primer cas, es poden indicar valors per defecte a una cel·la d’aquella columna. Això és útil, per exemple, quan, en emmagatzemar informació dins una BD, trobeu que alguns dels valors dins una cel·la encara no se saben. Se sabrà més endavant, però ara mateix el que no voleu és deixar d’emmagatzemar la informació que ja sabeu. Que el procés d’afegir una fila a una taula no sigui tot o res. Per dur a terme això, normalment el que es fa és disposar d’algun valor especial, o valor per defecte, amb el qual s’indica que en aquella cel·la no hi ha un valor vàlid encara.
Per fer-ho, s’usa el paràmetre DEFAULT valor. El valor pot ser un literal que indica exactament el valor per defecte, o bé es poden usar algunes paraules clau especials d’SQL:
| Valor | Descripció |
|---|---|
| NULL | Valor especial nul (marca d’invàlid). Semblant a una referència a null. |
| USER | El nom de l’usuari de la BD que ha executat la sentència. |
| CURRENT_DATE | La data actual, només per a camps de tipus DATE. |
| CURRENT_TIME | L’hora actual, només per a camps de tipus TIME. |
En relació amb les restriccions, n’hi ha unes quantes de disponibles, per la qual cosa ens centrarem en les més importants. Per una banda, hi ha les restriccions de columna, que indiquen condicions que ha de complir qualsevol accés a la BD per ser considerat vàlid. Si no es compleix la condició, la BD retorna un error. D’aquesta manera podeu garantir automàticament que les dades que es desen mantenen una coherència sense haver de fer-ho amb codi dins el vostre programa. Entre les més típiques es troben:
| Restricció | Descripció |
|---|---|
| PRIMARY KEY | La columna desa la clau primària de cada fila (els valors no poden ser repetits ni nuls). |
| NOT NULL | No s’admeten valors nuls. |
Per exemple, si es vol fer una taula de clients on el seu identificador serà la clau primària de cada client, es faria:
Amb la qual cosa es crea la taula (buida, de moment):
| ID | NOM | APOSTAL | AELECTRONICA | TELEFON |
Modificació de taules
Un cop una taula ja ha estat creada, és possible fer-hi modificacions, sense haver d’esborrar-la i crear-ne una de nova, usant la sentència ALTER TABLE.
Les accions possibles més rellevants ADD, ALTER i DROP, per afegir, modificar o eliminar una columna dins la taula. Cada acció usa un seguit de paràmetres semblants a quan es crea una taula des de zero, només que en aquest cas es tracta d’una definició a posteriori. La sinxati d’aquestes accions és:
En el cas de DROP, no cal definir res, ja que el que s’està fent és eliminar. Ara bé, com que les dades de la columna poden estar referenciades dins altres taules de la BD, cal preveure aquesta situació. Indicant el paràmetre RESTRICT, l’operació no es durà a terme si es dóna aquest cas. Amb el paràmetre CASCADE, tot el que referenciï aquesta columna també s’eliminarà.
Per exemple, si es vol afegir una columna amb el nombre de vegades que un client ha comprat a l’establiment, es pot fer:
Amb això, la taula CLIENTS passa a ser la següent:
| ID | NOM | APOSTAL | AELECTRONICA | TELEFON | NCOMANDES |
A part, també és possible canviar el nom d’una taula amb la sentència:
Esborrat de taules
En qualsevol moment també és possible eliminar totalment una taula de la BD a partir del seu nom. La sintaxi és la següent:
Els paràmetres RESTRICT i CASCADE tenen el mateix significat que en modificar una columna (de fet, esborrar una taula és com esborrar totes les seves columnes). Un cop eliminada, tota la informació que conté es perd, per tant, cal anar amb molt de compte en executar aquesta sentència.
Consulta de dades
La tasca més freqüent, la que segurament s’executarà més vegades en un programa que utilitza una BD, és de ben segur la cerca d’informació entre les dades que té emmagatzemades. Per fer-ho, es disposa de la sentència SELECT, que permet recuperar informació de la BD d’acord amb algun criteri. Atès que una cerca ha de ser capaç de poder englobar molts criteris, de manera que es trobi exactament la dada que es necessita, aquesta sentència pot incorporar opcions ben complexes. Per això, partirem de la seva sintaxi bàsica i després veurem com es pot anar refinant la cerca, ampliant-la.
Per anar seguint les diferents instruccions, partirem d’una taula anomenada CLIENTS, on es desen un seguit de clients amb certa informació. Sobre ella es veuran diferents exemples per a cada tipus de sentència:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | e-mail1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | e-mail2@domini.com | +34932223344 | 1 |
| 3 | Client3 | Adreça3 | e-mail3@domini.com | +34933334455 | 10 |
| 4 | Client4 | Adreça3 | e-mail4@domini.com | +34933335566 | 7 |
Per començar, la seva sintaxi base, que permet una cerca molt general, és:
En executar-la, la BD retorna les columnes demanades de la taula indicada. La part As nouNom, que es pot posar darrere el nom de cada columna, és opcional i permet reanomenar la columna tal com es mostra en el resultat, enlloc d’usar el nom original que hi ha a la taula.
El format de la resposta, com s’engloben les dades consultades, ja depèn del mecanisme usat per executar la sentència. Per exemple, si s’ha usat una aplicació gràfica, les columnes es poden mostrar en una nova taula reduïda, només amb les columnes desitjades. Si és un programa per línia de comandes, potser s’imprimeixen per pantalla com un text. O si es tracta d’un accés mitjançant codi en Java, com no podria ser d’altra manera, estaran englobades dins un objecte. De moment, però, no cal donar més voltes a aquest fet. N’hi ha prou a saber que, d’una manera o una altra, existirà un mecanisme per poder accedir al resultat sempre que s’executi aquesta sentència. Per ara, es visualitzarà la resposta d’una sentència SELECT com una nova taula.
Per tant, donades les següents sentències, si es volen enumerar només els noms i les adreces dels clients de la taula original, es faria així:
Sentència:
Resultat:
| NOM | ADREÇA |
|---|---|
| Client1 | Adreça1 |
| Client2 | Adreça2 |
| Client3 | Adreça3 |
| Client4 | Adreça3 |
Si, en lloc d’una llista de noms de columnes, s’usa un asterisc, *, es retornen tots els valors de la taula.
Sentència:
Resultat:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | e-mail1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | e-mail2@domini.com | +34932223344 | 1 |
| 3 | Client3 | Adreça3 | e-mail3@domini.com | +34933334455 | 10 |
| 4 | Client4 | Adreça3 | e-mail4@domini.com | +34933335566 | 7 |
També val la pena comentar que, en cas de taules on pot haver-hi valors repetits a les columnes, si es vol que en el resultat d’una consulta descarti repeticions, es pot usar SELECT DISTINCT, en lloc de només SELECT. L’exemple següent té en compte el fet que els clients 3 i 4 viuen al mateix lloc.
Resultat:
| APOSTAL |
|---|
| Adreça1 |
| Adreça2 |
| Adreça3 |
Aplicació de funcions
Ara bé, sovint, el que es vol no és pas simplement llistar tota la informació d’una columna, sinó només aquelles dades que compleixen certes condicions. Atès que les sentències de consulta són les més executades, el que no té sentit, o seria molt ineficient, és que només es pugui consultar un seguit de columnes senceres i després sigui tasca vostra haver de processar-les usant codi per refinar la cerca. Per exemple, cercar quin és el darrer client que s’ha donat d’alta, o si existeix algun client amb una adreça de correu electrònic concreta. Així doncs, en realitat, mitjançant la sentència SELECT és possible delegar aquesta tasca a la BD, que, en definitiva, és qui emmagatzema i gestiona tota la informació, de manera que tot plegat resulti més eficient.
Les funcions acceptades són semblants a les que existeixen als programes típics de full de càlcul.
Per una banda, SQL conté un seguit de funcions predefinides que es poden aplicar sobre les columnes, de manera que es demana a la BD que treballi, no sobre els valors de la columna, sinó sobre el resultat d’aplicar aquesta funció. Entre les més destacades:
| Funció | Descripció |
|---|---|
| MAX(nomColumna) | Retorna la fila amb el valor màxim en aquesta columna. |
| MIN(nomColumna) | Retorna la fila amb el valor mínim en aquesta columna. |
| SUM(nomColumna) | Retorna la suma de totes les files. |
| AVG(nomColumna) | Retorna el valor mitjà de totes files. |
| COUNT(nomColumna) | Retorna el nombre de files. |
| FIRST(nomColumna) | Retorna només la primera fila. |
| LAST(nomColumna) | Retorna només la darrera fila. |
| UCASE(nomColumna) | Transforma els valors de les files a tot majúscules. |
| LCASE(nomColumna) | Transforma els valors de les files a tot minúscules. |
| LEN(nomColumna) | Retorna la longitud dels valors a les files. |
| ROUND(nomColumna) | Arrodoneix els valors. |
Evidentment, les funcions només es poden aplicar sobre aquelles columnes de tipus de dades on tingui sentit. Per exemple, només es pot fer la suma dels valors d’una columna on es desin valors numèrics.
Cerques mitjançant condicions
Ara bé, sovint, en usar aquestes funcions, la semàntica de les dades consultades canvia. Per exemple, si es vol comptar el nombre d’elements que té la taula, i s’usa la funció COUNT, ara el valor retornat ja no es correspon estrictament al valor de cap columna en concret. No és ni un ID, ni un Nom… Per això, la sentència SELECT permet demanar a la BD que, quan retorni el resultat, reanomeni la columna transformada amb un altre nom. Això pot ser útil per fer més llegible el resultat, o, en definitiva, el codi d’un programa que la usi. Aquesta és la utilitat de l’apartat opcional AS nouNom.
Per exemple, si es vol veure quants clients hi ha a la taula CLIENTS, es podria fer la consulta següent:
Sentència:
Resultat:
| NCLIENTS |
|---|
| 4 |
Si bé la sentència SELECT, tal com s’ha vist fins ara, és suficient per recuperar dades de manera molt bàsica, és possible fer cerques molt més potents mitjançant l’addició del paràmetre opcional WHERE condició al final. Aquesta condició pot combinar diferents operadors, o fins i tot crides a les funcions SQL, de manera que arribi a ser tan complexa com es vulgui, sempre i quan s’avaluï a cert o fals, de manera molt semblant a les condicions d’una sentència condicional o iterativa d’un programa en Java (if, while…). En cas de combinar diferents condicions simples per fer-ne una de més complexa, aquestes es poden anar agrupant usant parèntesi, com al Java.
Els operadors que accepta SQL són els següents. Aneu amb compte, ja que alguns són diferents que en Java. Per exemple, la igualtat no és un doble igual ( == ), sinó només un ( = ).
| Operador | Descripció |
|---|---|
| = | Igual |
| < | Menor |
| ⇐ | Menor o igual |
| > | Major |
| >= | Major o igual |
| <> | Diferent |
| NOT | Negació lògica |
| AND | Conjunció lògica |
| OR | Disjunció lògica |
Recordeu que els literals de cadenes de text en SQL s’escriuen entre cometes simples, i no dobles cometes com al Java.
Per exemple, si es vol enumerar només els clients que viuen a l’adreça “Adreça3”, es podria fer la consulta que hi ha a continuació. En aquesta, és la pròpia BD qui s’encarrega de fer el processament i la discriminació dels elements, no cal que ho fem nosaltres després al codi del nostre programa, la qual cosa no només és molt més eficient des del punt de vista d’execució del programa, sinó que és més ràpid de codificar i fa el codi més simple.
Sentència:
Resultat:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 3 | Client3 | Adreça3 | e-mail3@domini.com | +34933334455 | 10 |
| 4 | Client4 | Adreça3 | e-mail4@domini.com | +34933335566 | 7 |
Ara bé, com s’ha dit, res no impedeix fer condicions complexes on s’usen també les funcions exposades amb anterioritat. Per exemple, si es vol cercar tots els noms dels clients que han fet un conjunt de compres inferior a la mitjana (i, ja de pas, els etiquetem com a “pitjors clients”), es podria fer la consulta que ve a continuació. El valor mitjà de comandes és 5.5, per la qual cosa, el resultat estableix els clients que tenen menys comandes que aquest valor.
Sentència:
Resultat:
| PITJORCLIENT |
|---|
| Client1 |
| Client2 |
Altres cerques mitjançant WHERE
Finalment, després d’un apartat WHERE també es poden afegir un seguit de paraules clau que permeten anar més enllà dels típics operadors lògics o matemàtics, de manera que encara es poden fer cerques més concretes, o d’acord a criteris encara més específics, però freqüents en el context d’una cerca. Aquestes opcions es poden combinar amb altres condicions per fer cerques encara més complexes. Tot seguit s’expliquen algunes de les més destacades.
L’opció IN, o NOT IN, permet indicar una llista de valors, de manera que la condició es considera certa si el valor d’una fila a la columna corresponent és (o no) entre algun dels valors de la llista. Per exemple, si es volguessin consultar els noms i correus electrònics dels clients que viuen a l’adreça postal 2 o 3 (fixeu-vos que hi ha dos clients que viuen a l’Adreça 3), es faria així:
Sentència:
Resultat:
| NOM | AELECTRONICA |
|---|---|
| Client2 | e-mail2@domini.com |
| Client3 | e-mail3@domini.com |
| Client4 | e-mail4@domini.com |
L’opció NULL, o NOT NULL, permet filtrar una consulta d’acord a les files que en alguna columna tenen un valor NULL, o no. Per exemple, si es vol obtenir una llisa de telèfons vàlids, partint de la suposició que es permet donar d’alta clients encara que no se sàpiga el seu telèfon, es pot fer d’aquesta manera:
Sentència:
Resultat:
| NOM | CLIENTSATRUCAR |
|---|---|
| Client1 | +34931112233 |
| Client2 | +34932223344 |
| Client3 | +34933334455 |
| Client4 | +34933335566 |
L’opció BETWEEN valorInicial AND valorFinal permet simplificar la creació de condicions on es vol veure si un valor es troba dins un rang. Per exemple, si es vol trobar el nom dels clients que han fet entre 3 i 8 compres, es faria amb aquesta sentència:
Sentència:
Resultat:
| NOM |
|---|
| Client1 |
| Client4 |
Finalment, l’opció LIKE patró permet establir si els valors compleixen un patró concret, en lloc d’haver de comparar una igualtat estricta. Això és molt útil, ja que sovint, en fer cerques sense saber exactament el contingut de les dades disponibles, el que es vol és trobar elements que compleixin de manera aproximada certes condicions, ja que a priori és impossible saber exactament què es pot cercar realment. El patró es representa com un literal de cadena de text, amb l’opció de posar un subratllat, ‘_’, per indicar qualsevol lletra, i un percentatge, '%', per indicar una seqüència de 0 o més lletres qualssevol.
Per exemple, suposem que es vol cercar el nom dels clients amb un número de telèfon on, en alguna part, hi ha dos nombres 4 consecutius. La consulta seria la següent:
Sentència:
Resultat:
| NOM | TELÈFON |
|---|---|
| Client2 | +34932223344 |
| Client3 | +34933334455 |
Ordenació dels resultats
Igual que la BD ja és capaç de dur a terme cerques d’acord a certs criteris usant les comandes adients d’SQL, de manera que no cal consultar totes les dades i després processar-les dins els vostres programes, també és possible establir criteris d’ordenació, de manera que el resultat ja està ordenat automàticament i no cal que ho feu vosaltres a posteriori.
Per assolir-ho, es pot usar el paràmetre ORDER BY nomColumna1, nomColumna2,… al final de la sentència SELECT. Aquest paràmetre ordena les files del resultat d’acord als valors de diferents columnes, per ordre d’importància. En el cas de valors de tipus cadena de text, s’ordenen els elements alfabèticament.
Per defecte, l’ordenació és ascendent, del valor més petit al més gran, però si es desitja es pot fer el cas invers usant la paraula clau DESC immediatament després del nom d’una columna. Per exemple, per mostrar els clients ordenats per nombre de compres, de manera que primer es mostra el que n’ha fet més, s’usaria la sentència:
Sentència:
Resultat:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 3 | Client3 | Adreça3 | email3@domini.com | +34933334455 | 10 |
| 4 | Client4 | Adreça3 | email4@domini.com | +34933335566 | 7 |
| 1 | Client1 | Adreça1 | email1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | email2@domini.com | +34932223344 | 1 |
Combinació de taules
De vegades, és necessari combinar la informació de diverses taules diferents per obtenir un únic resultat, sovint quan les condicions del paràmetre WHERE depenen de valors desats a altres taules. SQL permet fer operacions a partir de les dades de més d’una taula simplement especificant a l’apartat FROM que la informació a tractar prové de més d’una taula enlloc d’una, enumerades com una llista separada per comes: FROM nomTaula1, nomTaula2…. En principi, es poden combinar tantes taules com es vulgui, però ens centrarem en el cas de només dues taules.
Quan s’usa aquest mecanisme, per a cada nom de columna usada a qualsevol part de la sentència cal especificar a quina taula exactament s’està referint, no n’hi ha prou de posar només el nom de la columna. Això evita conflictes en duplicitats de noms entre taules diferents. Per fer-ho, només cal usar la sintaxi nomTaula.nomColumna, de manera molt semblant a l’accés a elements públics dins objectes en Java. Aquesta nomenclatura cal usar-la tant quan s’enumeren les columnes després del SELECT com dins la condició al WHERE, si n’hi ha.
Si els noms de les taules són llargues, pot passar que el text de la sentència sigui una mica farragós. Per això, en declarar les taules on fer la consulta, és possible assignar àlies abreujats, que poden ser usats a la resta de la sentència. L’àlies s’escriu directament després del nom de la taula.
Per veure-ho més clar, utilitzem un exemple. Suposem que existeix una nova taula PREMIS on s’enumeren premis de vals de descompte segons el nombre de compres acumulades d’un client. Pot ser interessant combinar la taula de clients amb aquesta per saber si a algun client li correspon alguna oferta.
| NCOMANDES | VAL |
|---|---|
| 5 | Un val de descompte del 5% a la propera compra. |
| 10 | Un val per a una tovallola de platja de regal. |
| 15 | Un val per a un 2 per un en qualsevol producte. |
| 20 | Dos vals de descompte de 10 euros en comandes diferents. |
Si es vol processar un enviament de vals de premi a les diferents adreces de clients que s’ho han guanyat, caldrà combinar les dues taules: saber quins premis mereix cada client i saber a quin nom i a quina adreça cal enviar el premi.
Sentència:
Resultat:
| NOM | APOSTAL | VAL |
|---|---|---|
| Client3 | Adreça3 | Un val de descompte del 5% a la propera compra. |
| Client3 | Adreça3 | Un val per a una tovallola de platja de regal. |
| Client4 | Adreça3 | Un val de descompte del 5% a la propera compra. |
Un fet molt important és veure com en el resultat s’han combinat dades de totes dues taules. Ara hi ha columnes tant de la taula CLIENTS com de la taula PREMIS, barrejades. Atès que el client 3 es mereix dos premis, ara apareix dues vegades repetit, una per cada cop que el seu nombre de compres compleix la condició establerta (major o igual que) amb qualsevol de les files a la columna NCOMANDES de la taula de PREMIS. Com que succeeix dues vegades, hi ha dues aparicions, i s’associa cada columna VAL a cada aparició. Bàsicament, la comparació es fa a nivell de totes les files d’una taula contra totes les files de l’altra, una a una.
En versions posteriors d’SQL, la sintaxi per dur a terme aquesta tasca s’ha modificat, de manera que per fer la mateixa tasca es pot usar un format de sentència diferent, mitjançant el paràmetre JOIN … ON …. Amb els dos es poden obtenir els mateixos resultats, però internament la consulta feta amb JOIN … ON … és molt més ràpida.
En aquest cas, la segona taula, que es pot considerar com a auxiliar, ja que és la que conté informació extra sobre la qual fer comparacions o extreure dades, s’identifica explícitament. La condició a la part ON indica també explícitament quina és la condició sota la qual es vinculen les dues taules. En aquesta sintaxi, pot ser que no calgui afegir el WHERE si amb la condició ON és suficient per vincular les dades entre taules.
Per exemple, la sentència per llistar els premis que cal enviar es podria adaptar a aquest altre format de la manera que es veu a continuació, amb idèntics resultats. Cal comptar que en aquesta consulta, la condició que vincula les dues taules és la relació entre les columnes NCOMANDES d’amdues, per la qual cosa, aquesta és la que correspon a l‘ON:
Sentència:
Un fet molt curiós de la unió de taules és que, de fet, res no impedeix operar amb la mateixa taula alhora, usant el mateix nom de taula al FROM i al JOIN. Tot i que pot semblar un cas molt estrany, suposeu la següent consulta: llistar tots els clients que han fet menys comandes que el client 4. Amb la unió de taules aquesta consulta és possible, ja que el que cal fer és creuar totes les dades de la taula CLIENTS amb les del client 4 (que també és a la mateixa taula). Per tant, es pot fer:
Sentència:
Resultat:
| NOM |
|---|
| Client1 |
| Client2 |
Per veure més clar què ha succeït, podeu dividir la sentència en dues parts. Per una banda, el WHERE indica que es treballa amb una versió de la taula CLIENTS, “c2”, on només hi ha els clients amb nom “Client4” (una única fila). Per altra banda, hi ha la taula “c1”, que és la versió completa (4 files). Llavors, mitjançant l‘ON, es fa la combinació de “c1” i “c2”, comparant totes les files d’una contra les de l’altra i obtenint només els casos on el valor de les comandes de “c1” és menor que el de “c2”. En total, 4 comparacions, i dues són certes, per als clients 1 i 2.
Manipulació de dades
L’objectiu final de disposar de taules correctament creades és, en definitiva, poder desar-hi informació per consultar-la o modificar-la posteriorment. Sense dades no té sentit poder fer consultes. Si bé res no impedeix que una BD tingui un conjunt de dades estàtic que mai no varia en el temps, i per tant ja n’hi ha prou d’afegir-les tot just després de crear la taula, el més normal, en una aplicació, és que les dades d’una taula puguin anar variant al llarg del temps, a mesura que es va afegint o eliminant informació.
Per dur a terme aquesta tasca, SQL disposa del conjunt de sentències corresponent que es poden executar sobre la BD. Tot seguit, veurem les més importants amb més detall.
Inserció de dades
Mitjançant la sentència INSERT INTO es pot afegir una nova línia a una taula concreta. La sintaxi base és:
Els termes “valor1”, “valor2” es corresponen als valors de cadascuna de les columnes de la taula en qüestió, enumerats exactament en el mateix ordre en què s’han enumerat les pròpies columnes en la creació de la taula i usant el mateix tipus de dades, de manera semblant, per exemple, a com s’especifica una llista de paràmetres en la crida d’un mètode (en el mateix ordre que en la seva definició). Evidentment, el nombre de valors també ha de concordar exactament amb el nombre de columnes. Si no es compleix alguna d’aquestes condicions, hi haurà un error.
Els valors individuals s’expressen com literals, tot i que també es pot usar la paraula clau NULL per indicar que es vol emmagatzemar un valor nul, o DEFAULT si volem que la BD emmagatzemi un valor per defecte. Ara bé, per poder fer això, cal que no s’entri en conflicte amb els paràmetres usats en definir la columna durant la creació de la taula. Per tant, per al primer cas, no es poden usar valors nuls si s’ha usat el paràmetre NOT NULL o PRIMARY KEY, i per al segon cas, cal que hi hagi realment un valor per defecte definit per a la columna. En cas contrari, no es procedirà a la inserció de les dades.
Per exemple, si sobre la taula CLIENTS s’executés la següent comanda d’inserció, llavors passaria a tenir la informació següent:
Sentència:
Taula resultant:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | e-mail1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | e-mail2@domini.com | +34932223344 | 1 |
| 3 | Client3 | Adreça3 | e-mail3@domini.com | +34933334455 | 10 |
| 4 | Client4 | Adreça3 | e-mail4@domini.com | +34933335566 | 7 |
| 5 | Client5 | Adreça5 | e-mail5@domini.com | +34933336677 | 3 |
Eliminació de dades
Si mai es vol esborrar una fila, o un conjunt de files, cal usar la sentència DELETE. Aquesta usa el paràmetre WHERE, de manera idèntica a quan es fan consultes, però ara com a criteri d’esborrat. Per tant, aquelles files que en una sentència SELECT serien el resultat, en una sentència DELETE són les esborrades. Un cop més, la condició pot ser tan complexa com es desitgi i, fins i tot, es poden usar funcions SQL (esborrar la fila amb el valor més baix, la primera fila).
Per exemple, per eliminar de la taula original (amb 4 clients) tots els que viuen a l’adreça 3, es faria així:
Sentència:
Taula resultant:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | email1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | email2@domini.com | +34932223344 | 1 |
Modificació de dades
Un cop es disposa ja de dades dins la taula, també es poden modificar directament, sense haver d’esborrar-les i afegir-les de nou. La sentència UPDATE permet canviar el valor d’una cel·la. La sintaxi és:
Per seleccionar només una fila, pot resultar molt útil usar la clau primària de la taula dins la condició.
Els paràmetres després de SET indiquen quins són els nous valors per a un conjunt de columnes, que poden ser totes o només una part, de manera que se seleccionen exactament les cel·les a canviar. La condició dins el WHERE serveix, novament, per delimitar quines files cal considerar de cara a l’actualització. Si més d’una fila compleix la condició, s’actualitzen totes amb els valors indicats. Per tant, cal anar amb una mica de compte en aquest cas i, si volem modificar només una cel·la, assegurar-se que la condició delimita exactament una única fila.
Per exemple, si volem canviar l’adreça del client 4 per una de nova, es podria fer així:
Sentència:
Taula Resultant:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | email1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | email2@domini.com | +34932223344 | 1 |
| 3 | Client3 | Adreça3 | email3@domini.com | +34933334455 | 10 |
| 4 | Client4 | novaAdreça | email4@domini.com | +34933335566 | 7 |
Com en el cas de la inserció, es poden usar els valors especials DEFAULT o NULL. També és possible usar expressions com a nou valor d’actualització, en el cas de dades numèriques: sumes, restes… Per exemple, si des de l’adreça 3 s’han fet 5 comandes noves, es podria fer amb aquesta sentència:
Sentència:
Taula Resultant:
| ID | NOM | APOSTAL | AELECTRONICA | TELÈFON | NCOMANDES |
|---|---|---|---|---|---|
| 1 | Client1 | Adreça1 | email1@domini.com | +34931112233 | 4 |
| 2 | Client2 | Adreça2 | email2@domini.com | +34932223344 | 1 |
| 3 | Client3 | Adreça3 | email3@domini.com | +34933334455 | 15 |
| 4 | Client4 | Adreça3 | email4@domini.com | +34933335566 | 12 |
JDBC
Java proporciona l’API Java Database Connectivity (connectivitat Java a bases de dades) com a mecanisme per poder generar i invocar sentències SQL sobre un BD relacional mitjançant codi en programes Java. La seva particularitat és que, en contrast amb altres sistemes existents, ofereix una interfície comuna per a l’accés a qualsevol tipus de BD, independentment del fabricant. Per al desenvolupador, la BD real que hi ha al darrere és totalment transparent i obvia la necessitat d’efectuar cap mena de configuració en la màquina on s’executa l’aplicació que accedeix a les dades. Aquesta biblioteca es troba principalment en els paquets java.sql i javax.sql.
El controlador de BD Microsoft és sun.jdbc.obdc.
JdbcObdcDriver.
Partint de la suposició que ja hi ha una BD correctament configurada i a la qual volem accedir des del codi d’un programa Java, el resum de passos que cal fer dins l’aplicació és:
- Importar correctament els packages corresponents.
- Carregar el controlador (driver) per a l’accés a la BD. Aquest depèn de la BD a accedir.
- Establir la connexió a la BD.
- A partir d’aquí, ja es poden executar sentències SQL en la BD i processar les respostes.
- Quan ja no es vol treballar més amb la BD, cal tancar la connexió.
JDBC, igual que moltes altres API en Java, està dissenyat amb la simplicitat en el pensament i intenta que l’ordre de les operacions que ha de fer l’operador sigui genèric i, fins a cert punt, lògic. Igual que per llegir dades d’un fitxer el que cal fer és dir quina és la seva ubicació, obrir-lo, llegir o escriure les dades i tancar-lo, en aquest cas la idea és similar. Simplement, “llegir-lo o escriure’l” vol dir invocar una sentència SQL, enlloc de posicionar un apuntador. Tot i així, cal tenir un cert domini d’SQL per poder fer correctament aquesta feina, és clar.
Tot seguit, es veurà amb més detall els passos més importants (es dóna per feta la importació correcta de packages), però només a títol d’introducció, per fer-se una idea del significat de cada pas. Es mostra un fragment de codi que consulta tots els clients d’una BD i en mostra el nom i l’adreça postal per pantalla. En aquest cas, totes les classes implicades en l’accés a una BD pertanyen al paquet java.sql.
Càrrega del controlador
Per permetre la independència de la plataforma, JDBC proporciona un gestor de controladors que gestiona dinàmicament tots els aspectes específics de l’accés a un tipus de BD concret. JDBC és qui s’encarrega de transformar totes les crides genèriques als accessos corresponents d’acord als mecanismes específics de la BD amb què s’interactua. Com a desenvolupadors, us podeu desentendre, fins a cert punt, de tots aquests detalls. Per tant, si es disposa de quatre tipus diferents de bases de dades, de diferents fabricants, per connectar-se caldrà disposar de quatre controladors diferents.
Els controladors sempre prenen la forma d’una classe Java, identificada de manera absoluta amb el nom complet del paquet que la conté i el nom de la classe en si. El seu registre de controladors es fa automàticament quan es carrega la classe a memòria, cosa que es fa amb la crida Class.forName(nomControlador). Des del punt de vista del programador, no cal fer res més. Per exemple, per a l’accés a una BD Apache Derby, cal carregar el seu controlador específic, amb la crida següent:
Atès que aquest controlador només serveix per a aquest tipus de BD, si s’intenta usar per connectar-se a una BD de qualsevol altre tipus (Oracle, PostgreSQL…), el programa no funcionarà.
El CLASSPATH indica on es troben les classes accessibles quan s’executa un programa Java.
Cal tenir en compte que el fet que des del punt de vista del desenvolupador la càrrega del controlador sigui senzilla no vol dir que el procés de disposar i configurar correctament un controlador sigui immediata. La classe que conté el controlador del SGBD serà diferent per a cada cas, per la qual cosa cal consultar la documentació del fabricant del programari per esbrinar quin és el nom de la classe en qüestió i saber com instal·lar-la al sistema. Tot i que per carregar el controlador no cal usar cap instrucció import, sí que cal que aquesta classe estigui inclosa en el CLASSPATH perquè es pugui localitzar correctament.
En usar JDBC, la instrucció “Class.forName” és l’única que canvia, d’acord al tipus concret de BD al qual s’accedeix. La resta d’instruccions del programa serà exactament igual, sempre que no s’usin extensions propietàries de l’SQL.
Establiment de la connexió
Un cop s’ha carregat correctament el controlador, l’aplicació es pot connectar remotament a algun servidor que conté la BD mitjançant la crida al mètode estàtic getConnection de la classe DriverManager que es descriu a continuació. Aquesta classe ofereix els serveis bàsics de gestió de controladors JDBC i és el punt d’accés a ells des dels vostres programes.
La definició d’aquest mètode és:
Un URL és el que s’escriu en la barra d’adreces d’un navegador web per accedir a una pàgina web concreta.
El paràmetre “url” és una cadena de text amb l’identificador de la ubicació de la BD. Quan es configura una BD, aquesta normalment ens informa de quin és aquest identificador, que dependrà en part de la màquina on s’ha instal·lat.
Un URL (uniform resource locator, localitzador uniforme de recurs) és un apuntador a algun recurs o servei disponible a internet. Aquest recurs pot ser quelcom tan simple com un fitxer, o elements més complexos com objectes, un servidor web o, és clar, una BD accessible remotament.
Adreça IP
Es tracta d’un identificador únic per a cada màquina connectada a internet. Consta de 4 bytes i normalment es representa amb cada byte en notació decimal, separats per punts. Per exemple: 192.168.0.34
A nivell general, normalment, un URL es caracteritza perquè està dividida en fragments prou significatius:
- El protocol que cal usar per accedir al recurs. O sigui, quin serà el format de les dades que arribaran al servei, de manera que les pugui interpretar correctament.
- El nom de la màquina, o la seva l’adreça IP, de manera que s’identifica a l’equip on es troba disponible el recurs o el servei.
- El port del servei, un identificador únic assignat a tots els serveis que s’executen en la màquina, de manera que és possible dirigir peticions a un servei concret donada una màquina.
- Finalment, especifica el nom del recurs pròpiament dins la màquina.
Així, doncs, un URL és, per exemple:
http://ioc.xtec.cat:80/educacio/ioc-estudis
Indica que, mitjançant el protocol anomenat HTTP, el que usa la web, cal accedir al port 80, on se sol executar el servidor web, i obtenir el recurs ”/educacio/ioc-estudis”, que és una pàgina web.
En el cas d’un URL per accedir a una BD mitjançant JDBC, té la particularitat que la part del protocol es divideix en dos: el protocol principal, que és “jdbc” i el subprotocol. Sense entrar en detall, es tracta d’un identificador que especifica el nom del controlador o mecanisme de connectivitat a la BD que cal usar. Per exemple, per a un servei de BD Apache Derby, el subprotocol és “derby”. Cal mirar la documentació de la BD. La resta de la URL és idèntica a qualsevol altra: nom de màquina, port on s’executa el servei de la BD i nom de la BD concreta a què es vol accedir.
Per accedir a la BD anomenada “gestioEncarrecs” a un servei de BD de tipus Apache Derby que s’executa al port 1527 de la màquina amb adreça IP 192.168.2.1, la URL seria la següent:
L’identificador localhost es pot usar si la màquina a la qual s’accedeix és la mateixa on s’executa l’aplicació.
Sempre que es desplega una BD, normalment es poden configurar comptes d’usuari, protegides amb contrasenya, de manera que no es permet que qualsevol aplicació aliena pugui llegir alegrement les dades contingudes. Per tant, perquè el programa pugui accedir a la BD, si està correctament protegida, també caldrà disposar d’un nom d’usuari i d’una contrasenya correctes, que és el que representen els paràmetres “user” i “psw”. Si no hi ha cap compte d’usuari o contrasenya habilitat, cosa poc recomanable, es pot posar un text buit (””) als dos paràmetres.
Si la connexió remota s’estableix de manera correcta (la BD realment existeix, el servei està en marxa, correctament configurat i no hi ha cap problema en la xarxa), es retorna una instància de la classe Connection, a partir de la qual es pot interactuar per dur a terme qualsevol acció amb la BD. Per tant, el codi per connectar-se a la BD amb la URL anterior, si s’ha configurat amb un compte d’usuari “administrador”, amb la contrasenya “pswdificil”, seria:
Val la pena comentar que, tot i que a l’exemple els paràmetres de la crida estan definits com a cadenes de text al mateix codi de l’aplicació, en una aplicació real aquesta seria una solució poc encertada, ja que si mai canvia la ubicació de la BD (la màquina o el port) o el seu nom, caldria modificar el programa i tornar a compilar el programa. En la realitat, aquesta informació hauria de ser configurable, de manera que es pugui canviar sense haver de tocar el codi del programa. Per exemple, en un fitxer de configuració o com a paràmetre d’execució.
Execució de sentències SQL
Totes les interaccions amb la BD pràcticament sempre s’efectuen mitjançant l’enviament i l’execució de sentències SQL i el processament de les respostes. Les sentències SQL prenen la forma de simples cadenes de text que podeu generar al vostre gust (CREATE TABLE…, INSERT…, SELECT……), sempre que sigui amb la sintaxi correcta. En aquest aspecte, res no varia.
Un cop es disposa de la cadena de text amb la sentència que es vol invocar a la BD, el mecanisme ofert per JDBC per enviar-les a través d’una connexió establerta és mitjançant l’ús de la classe Statement (sentència). Si es tracta d’una operació de consulta de dades, JDBC processa la resposta de la BD i la presenta dins el programa com un objecte del tipus ResultSet, del qual podem extreure la informació associada a partir dels mètodes que proporciona aquesta classe. Ambdues es troben al package java.sql.
La classe Statement
És possible assignar valors per defecte usant el mètode sense paràmetres createStatement().
Les instàncies de la classe Statement només es poden instanciar mitjançant la crida al mètode createStatement, de la classe Connection. No es pot invocar directament el constructor usant el new (de fet, aquesta classe és, en realitat, una interfície Java).
Els paràmetres d’entrada especifiquen quines seran les propietats de les respostes de l’execució de la sentència, només per al cas d’executar consultes (SELECT). Dins la classe ResultSet és on es poden trobar definides el seguit de constants estàtiques que s’accepten com a paràmetre. Entre les més destacades es troben:
| Paràmetre | Constant | Descripció |
|---|---|---|
| tipus | ResultSet.TYPE_FORWARD_ONLY | La resposta només es pot navegar unidireccionalment, només endavant. És el que normalment s’usa. |
| tipus | ResultSet.TYPE_SCROLL_INSENSITIVE | La resposta només es pot navegar endavant i endarrere. |
| tipus | ResultSet.TYPE_SCROLL_SENSITIVE | Com l’anterior i, a més a més, si hi ha canvis a la mateixa BD mentre s’usa la resposta, aquests es reflecteixen a les dades que conté. |
| concurrència | ResultSet.CONCUR_READ_ONLY | Les dades contingudes a la resposta no es poden modificar (mode de lectura, només). |
| concurrència | ResultSet.CONCUR_UPDATABLE | Les dades contingudes a la resposta es poden modificar (mode lectura-escriptura). |
Cal tenir en compte, però, que no tots els controladors permeten totes aquestes opcions.
Els mètodes sobrecarregats permeten recuperar valors per número de columna, segons l’ordre que ocupi en la taula…
Un cop s’ha inicialitzat correctament l’objecte i ja es disposa de la cadena de text amb la sentència SQL, aquesta sentència es pot enviar a la BD invocant el mètode corresponent. En el cas d’una consulta de dades (SELECT), cal emprar el mètode executeQuery, mentre que en qualsevol altre cas (INSERT, UPDATE, DELETE), quan es fan modificacions al contingut de la mateixa BD, cal usar el mètode executeUpdate. Ambdós estan sobrecarregats, de manera que permeten concretar certes particularitats de l’execució de la sentència. La crida més senzilla és la que té com a paràmetre, simplement, la cadena de text amb la sentència SQL a enviar.
Si no es produeix cap excepció, llavors això voldrà dir que la sentència s’ha executat correctament. Fixeu-vos que només en el primer cas, quan es fa una consulta, realment es retorna un conjunt de dades. El valor de retorn d’una modificació sol ser 0, o el nombre de files que han estat manipulades per la sentència.
Per exemple, per consultar tots els clients que viuen a l’adreça 3 d’una taula, es faria:
D’altra banda, si es vol afegir un nou client, llavors caldria fer:
Estrictament, la dificultat en l’execució de la sentència mitjançant la classe Statement recau íntegrament en la vostra habilitat per crear sentències SQL sintàcticament i semànticament correctes. Com passava en crear la connexió, recordeu que les sentències no han de ser necessàriament cadenes de text estàtiques definides dins el codi (segurament, poques vegades ho siguin), també poden dependre d’altres variables o d’altres paràmetres. Per exemple:
La classe PreparedStatement
Mitjançant la classe Statement es pot executar qualsevol sentència SQL sense límit. Ara bé, molt sovint, en un programa que accedeix a una BDD, l’usuari no disposarà de la possibilitat de fer qualsevol consulta que es pugui imaginar, sinó que es trobarà limitat a les funcionalitats que proporciona la seva interfície d’usuari. Així doncs, per exemple, en un programa que gestiona encàrrecs de clients usant una interfície gràfica, hi haurà un seguit de menús o botons que enumeraran un seguit d’operacions finites i molt concretes que es poden dur a terme: llistar noms de clients ordenats alfabèticament, cercar els encàrrecs pendents d’un client… Mitjançant sentències SQL es poden fer consultes ben complicades, però el programa ja té dins el seu codi un conjunt que són les úniques que s’usaran mai. L’usuari normalment no haurà de treballar directament amb el llenguatge SQL (SELECT, INSERT…), només indicar certs paràmetres molt concrets de la consulta (el nom del client a cercar, les dades d’un client que es volen llistar).
La classe PreparedStatement és una subclasse de Statement que permet executar sentències parametritzades, de manera que facilita aquest tipus de comportament dins un programa. La seva particularitat principal és l’eficiència superior en relació amb Statement, ja que en el moment de definir-la es precompila, de manera que estalvia feina a la BDD. Per tant, és preferible usar-la per a sentències senzilles que depenen de paràmetres molt concrets aportats per l’usuari, i que cal usar repetides vegades, només canviant aquests paràmetres, al llarg de l’execució del programa.
Per instanciar un objecte PreparedStatement, també cal cridar un mètode estàtic de la classe Connection (n’hi ha diversos, en estar sobrecarregat). Ara bé, en aquest cas, hi ha un paràmetre addicional, que és la sentència SQL parametritzada. En aquesta sentència, el text no està complet, sinó que s’escriu un interrogant ('?’) a cada lloc on es vol ubicar un paràmetre. Per exemple, suposem que un programa vol usar aquesta classe per dur a terme la funció de cercar les dades d’un client donat el seu nom.
Alerta, els valors dels índexs dels paràmetres van de 1..N, no de 0..N com en altres classes que gestionen llistes.
Atès que la sentència parametritzada no és vàlida en si mateixa, abans de poder-la executar cal assignar valors als seus paràmetres, un per a cada interrogant dins el seu text. Internament, l’objecte PreparedStatement organitza els paràmetres ordenant-los amb un índex de 1 a N, de manera que el primer '?’ és el paràmetre 1, el segon és el 2… Mitjançant un seguit de mètodes, permet assignar valors a cadascun dels índexs. Hi ha un mètode per a cada tipus de dades. Cal invocar-ne tants com paràmetres (nombre d’interrogants) hi ha al text de la sentència.
setString(int parameterIndex, String x)setInt(int parameterIndex, int x)setDouble(int parameterIndex, double x)- etc.
Evidentment, cal ser molt acurat i usar el mètode que correspon al tipus de dades d’acord a la definició de la BDD, de manera que la sentència final sigui correcta. Per exemple, si s’està fent una cerca per nom de client, en l’exemple anterior caldrà usar el mètode setString per assignar correctament el paràmetre, ja que la columna NOM és de tipus VARCHAR (una cadena de text). Un cop l’objecte està correctament inicialitzat amb els valors dels paràmetres adients, de manera que cap queda sense un valor assignat, es pot executar usant executeQuery o executeUpdate, com amb Statement. Aquest cop, però no cal definir cap sentència en cridar aquests mètodes.
La classe ResultSet
La instància de ResultSet retornada per una crida executeQuery conté la llista de files resultant de la consulta a la BD. Si la consulta no ha obtingut cap resultat, la instància de ResultSet estarà buida, però mai no es donarà el cas que retorni una referència a null. Si hi ha cap error (la sentència SQL executada no era correcta), es produirà una excepció.
ResultSet ofereix els mètodes necessaris per navegar per la llista i accedir als valors emmagatzemats. Aquesta navegació sempre és fila per fila, però el mode d’accés variarà segons els paràmetres emprats en instanciar l’objecte Statement associat: unidireccional, de manera semblant a com ho faria un Iterator, o bidireccional. En qualsevol dels casos, l’objecte ResultSet disposa d’un apuntador intern on recorda quina és la posició actual. Mitjançant la invocació de certs mètodes (next() o previous()), es pot fer avançar o recular l’apuntador. Ambdós s’avaluen a true si la nova posició de l’apuntador després de desplaçar-se conté una fila vàlida, o false si ja ens hem passat de la llista, tant sigui per l’inici com o pel final.
En el cas d’un ResultSet unidireccional, un cop s’arriba al final, ja no es pot accedir més a les dades. Cal tornar a executar una consulta.
Aquest sistema té la particularitat que, a l’inici de tot, l’apuntador està una posició per endavant de la primera fila, de manera que la primera crida a next() sempre es posiciona a la primera fila. Per tant, si s’intenta obtenir cap dada des del ResultSet, només obtenir-la, sense posicionar-se almenys en alguna fila correcta, hi haurà un error.
Un cop posicionats en la fila que es vol llegir, és possible consultar el valor de les cel·les per a cada columna definida en la taula, usant el nom de la columna. Per fer-ho, cal cridar el mètode getXXX adequat segons el tipus de dades de la columna a consultar, usant com a paràmetre el nom de la mateixa columna. En escollir quin mètode usar per obtenir les dades d’una columna concreta, cal tenir en compte les equivalències entre tipus de dades SQL i Java. Per exemple, si la dada a la BD és de tipus INTEGER, no podeu usar un mètode per obtenir una cadena de text (getString), i viceversa. Si el valor emmagatzemat en la columna no es correspon amb el tipus de dades del mètode cridat, es produirà un error. Dins el ResultSet totes les dades ja s’hauran convertit del tipus original SQL a la BD a tipus tractables en el codi Java, per la qual cosa no cal fer cap conversió concreta, només ser conscients de les equivalències.
Existeix un mètode per a cada tipus de dades, per exemple:
String getString (String nomColumna)int getInt (String nomColumna)short getShort (String nomColumna)double getDouble (String nomColumna)java.sql.Date getDate(String nomColumna)- etc.
Cal anar amb compte, però, amb la possibilitat que el valor que hi ha a la cel·la de la BD sigui NULL i, per tant, invàlid. En el cas dels mètodes que retornen objectes (String, Date), aquests senzillament retornaran una referència a null, en aquest cas. Ara bé, en el cas de mètodes que retornen un tipus primtiu, el resultat serà 0 (o false per als booleans). En aquest cas, com que no és possible a simple vista saber si el 0 en qüestió és perquè el valor és realment un 0 o NULL, cal usar el mètode auxiliar wasNull(), immediatament després de la crida a getXXX, el qual ens dirà si el valor retornat a la darrera consulta era un valor NULL a la BD o no.
Si es vol llistar per pantalla la llista dels noms de tots els clients de la BD, es pot fer així:
Aquest codi faria exactament el mateix si, en lloc de consultar només els noms, a la sentència SQL es consultessin totes les dades (SELECT *), o qualsevol subconjunt de dades que inclogués el nom (SELECT NOM, APOSTAL…). Atès que la crida a getString especifica la columna que vol extreure del resultat, s’obtindrien sempre les mateixes dades per pantalla. Ara bé, recordeu que, si es vol fer un codi eficient i no carregar la BD innecessàriament, cal escriure sentències SQL que es limitin a consultar estrictament les dades que necessiteu i cap altra.
Finalment, val la pena comentar que encara que un ResultSet només sigui navegable unidireccionalment, per exemple perquè no queda més remei ja que la BDD no suporta l’execució de consultes que retornin navegació bidireccional, això no vol dir que us hàgiu de resignar i haver de recórrer diverses vegades les dades per fer diferents operacions amb les mateixes dades dins un programa. Recordeu que res no impedeix agafar els valors i desar-los en estructures Java que sí que permetin gestionar la informació de manera més còmoda, com ara Lists, Sets o Maps, i, a partir d’aquí, treballar amb elles.
Modificacions a les dades via ResultSet
Si a l’hora d’instanciar l’objecte Statement s’ha definit que el ResultSet retornat és de lectura-escriptura (paràmetre tipus ResultSet.CONCUR_UPDATABLE), llavors també és possible modificar el contingut de les files que conté, de manera que la manipulació es trasllada a la BD. És una manera alternativa de fer actualitzacions a la BD des d’una perspectiva més d’orientació a objectes, manipulant instàncies, en lloc d’usar sentències de text SQL.
Aquest sistema és possible ja que la generació d’un ResultSet no es basa a executar la resposta a la BD, obtenir absolutament totes les dades corresponents, encapsular-les, retornar-les al codi Java via JDBC, i oblidar-nos de la BD. En realitat, internament, un ResultSet és una associació viva amb la BD, que va obtenint les dades a poc a poc des de la BD a través de la connexió, a mesura que es van consultant les files de la resposta. Això permet que, igual que es pot llegir, també es pugui escriure a través d’aquesta associació. O que, si hi ha canvis a la BD, surtin immediatament també al ResultSet sense haver d’esperar a fer una altra consulta (si s’ha usat el paràmetre ResultSet.TYPE_SCROLL_SENSITIVE).
Com amb una simple consulta, cal posicionar-se a la fila a modificar. En aquest cas, els mètodes d’escriptura s’anomenen updateXXX, de manera anàloga als de lectura. En termes generals, tot el que s’aplica als mètodes de lectura, com el tractament de tipus de dades Java-SQL, s’aplica a aquests.
void updateString (String nomColumna, String s)void updateInt (String nomColumna, int i)short getShort (String nomColumna, short s)double getDouble (String nomColumna, double d)void updateDate(String nomColumna, java.sql.Date d)- …
No obstant això, si es vol escriure un valor NULL, el que cal usar és el mètode updateNull(String nomColumna), independentment del tipus de dades desat a la columna.
Ara bé, un cop feta la modificació al ResultSet, en ser un conjunt de dades locals a l’aplicació, cal avisar-lo que forci una actualització sobre la BD. Això es fa amb el mètode updateRow(). Aquest mètode actualitza la informació només de la fila on es troba actualment l’apuntador i cap altra.
Per exemple, el codi següent passa a majúscules els noms de tots els clients de la BD, aprofitant els mètodes que ofereix Java per manipular cadenes de text. Fixeu-vos que ara el segon paràmetre de creació de l‘Statement és ResultSet.CONCUR_UPDATABLE.
Un cop més, cal ser curós de no consultar més dades a la BD de les imprescindibles per fer la tasca encomanada (no fer SELECT * si realment no hem de treballar amb totes les dades al final).
A part de modificar dades, també és possible afegir i eliminar files. Per al primer cas, s’usa primer el mètode moveToInsertRow(), per indicar que la posició actual es considera ara una fila nova, una successió de crides a updateXXX per posar les dades a cada columna, i finalment el mètode insertRow(). Per eliminar la fila actual, només cal invocar el mètode deleteRow().
Tancament de la connexió
El manteniment d’una connexió oberta a una BD és una tasca costosa per al sistema, tant pel vostre programa com pel servei de BD a l’altre extrem de la connexió; per tant, quan ja no s’ha d’usar més, cal tancar-la, de la mateixa manera que cal tancar un flux després d’haver-ne llegit tota la informació. El tancament s’efectua, simplement, cridant sobre la connexió (l’objecte Connection) el mètode close:
En qualsevol cas, si un se n’oblida, la connexió no es manté oberta indefinidament, ja que quan el recol·lector de memòria de Java elimini l’objecte Connection generat també s’encarregarà de tancar la connexió. De totes maneres, aquest mecanisme és només un últim recurs que proporciona Java en cas que us hàgiu despistat. Cal que sempre tanqueu vosaltres la connexió al codi.
Atès que el procés de creació d’una connexió també és costós, les aplicacions que fan ús de l’accés a una BD normalment obren una connexió en iniciar-se i no la tanquen fins tot just abans d’acabar-ne l’execució. De totes maneres, si es preveu que l’aplicació no farà ús de la connexió en un interval llarg de temps, val la pena tancar-la i tornar-la a obrir quan realment torni a fer falta, ja que si el servei de la BD té limitat el nombre de connexions, pot ser que el nostre programa estigui impedint que un altre s’hi connecti, tot i no estar accedint realment a la BD.
Exemple d'aplicació JDBC: El gestor d'encàrrecs
Tot just es mostra el codi d’un exemple d’aplicació que usa JDBC per gestionar informació a una BD. Concretament, aquest programa gestiona objectes de tipus Client de manera que les seves dades es troben a una BD a través de la qual es poden fer cerques o afegir-ne. Es composa de tres classes:
Client, que defineix quina informació conté un client.GestorBD, que conté els mètodes associats a l’accés a la base de dades.GestorEncarrecs, que és la classe principal i ofereix la interfície d’usuari (per consola).
Abans de poder-la executar correctament, es clar, s’ha d’haver configurat correctament una BD d’acord al codi de connexió a GestorBD.
Seguretat en l'accés a la BD
Una BD que s’executa en una màquina és una porta d’accés a totes les dades emmagatzemades, les quals moltes vegades són confidencials (noms, adreces, etc.). Protegir aquestes dades, de manera que només les persones realment autoritzades les puguin llegir, és una tasca molt important, no tan sols de l’administrador del SGBD (per exemple, configurant un nom d’usuari i contrasenya prou segurs), sinó del mateix desenvolupador d’aplicacions. Si una aplicació que accedeix a una BD no es codifica correctament, pot succeir que persones no autoritzades poden arribar a accedir a les dades aprofitant males pràctiques en el codi. Per tant, quan es treballa amb una BD és molt important programar de manera segura.
Mitjançant la disciplina de la programació segura, es pot donar un cert nivell de garantia que una aplicació es comportarà sempre de la manera esperada i un usuari amb males intencions no serà capaç de comprometre el sistema aprofitant errors en el codi.
Aquesta disciplina és molt extensa, però no es pot finalitzar aquest capítol sense mostrar algun exemple significatiu dels aspectes que cal tenir molt en compte en crear una aplicació que accedeix a una BD.
Un dels punts més importants en desenvolupar aplicacions d’aquest tipus és que, quan s’executen sentències SQL, en cap concepte aquestes han d’incloure directament cap tipus d’entrada de l’usuari. Totes les entrades s’han de validar prèviament i s’ha de comprovar si tenen el format esperat.
Suposem el fragment de codi següent, que permet fer cerques sobre la taula donats noms coneguts de clients:
Si l’usuari introdueix la cadena “Client1”, s’executa la sentència SQL:
De manera que, en fer l’accés a la BD, l’aplicació retorna una sortida de l’estil:
Els clients trobats són:
| Client1 | Adreça1 | email1@domini.com | +34931112233 | 4 |
Si hi ha més d’un client amb el nom “Client1”, es llisten diverses files de la taula. Fins aquí, tot correcte. També, d’acord amb aquest fragment de codi, un usuari no pot accedir a les dades d’un client si no en coneix el nom, ni molt menys llistar tota la taula de cop. Sempre es podrien provar totes les combinacions possibles de noms, però intuïtivament ja es veu que aquesta via d’acció no és realment factible. Fins i tot en cas que es vagin provant noms a l’atzar, mai no es pot estar segur de tenir realment tot el contingut de tota la taula.
Ara bé, en aquest codi es comet el gegantí error d’utilitzar directament l’entrada de l’usuari per formar una sentència SQL de consulta (SELECT). Suposem que com a nom d’usuari s’introdueix la cadena de text següent: “Client1’ OR ‘1’=‘1”.
Atès que el codi traspassa directament l’entrada de l’usuari a la sentència SQL mitjançant una concatenació de cadenes de text, llavors la sentència que realment s’executaria seria:
Ara l’expressió que s’executa és una mica estranya i inesperada, però és el resultat d’aplicar exactament el procés que s’ha programat. En aquest cas, com ‘1’=‘1’avalua cert i una expressió OR amb una de les seves entrades a cert sempre retorna també cert, això equival a fer:
Per tant, s’acaba de llistar tota la taula de clients de manera inesperada a causa de la manca de comprovació del format de l’entrada de l’usuari abans de traspassar-la a una sentència SQL. Això és un error molt greu per part del desenvolupador. L’administrador del SGBD no hi pot fer res que protegeixi la màquina on es troba la BD contra aquest error, ja que es tracta d’un error de programació, no de configuració de la BD.
Malauradament, aquesta vulnerabilitat és molt comuna (entre les cinc primeres del rànquing mundial), especialment en aplicacions basades en formularis web. Es coneix com a SQL-Injection.
Una eina útil per fer comprovacions en el format de cadenes de text d’entrada són les expressions regulars.
Per evitar aquest problema, cal que el codi dels vostres programes processi qualsevol cadena de text que depèn d’una entrada de l’usuari abans de permetre que formi part del text d’una sentencia SQL. Per exemple, es pot veure si les dades introduïdes tenen el format esperat. No hi ha gaires telèfons o adreces de correu electrònic amb apòstrofs o símbols d’igualtat. Una altra opció és marcar els apòstrofs que hi ha dins una entrada de dades de l’usuari de manera que la BD no els interpreti com part de la sintaxi SQL, sinó com un caràcter qualsevol estrictament. Cada sistema de BD ofereix la seva manera d’escapar caràcters i diferenciar entre un caràcter especial d’SQL o un que són dades estrictament.
Una altra opció és usar sentències parametritzades, PreparedStatement, ja que aquestes són immunes a aquest atac.